The primary focus of this release is the addition of plugins. A plugin allows for processing a key and/or value in order to further process the data available within. For example, UserAssist is Rot13 encoded, so the plugin for UserAssist would un-Rot13 the value names and extract other meaningful things from values. All of this information is then returned from the plugin and displayed to the user. The data returned from a plugin can then be sorted, filtered, exported, and so on.
We will cover all of the available plugins that are shipping with this release below.
Before getting into plugin details and some of the other more interesting changes, let's take a look at the changelog.
The changes in this version include:
NOTE: The manual has been updated to reflect everything available in this version. For more details on any of these features, Read The Friendly Manual.
NEW: Change to .net 4.6
NEW: Added exporting of values to Excel, TSV, PDF, and HTML via key context menu (under Export | Values). Data is exported exactly as shown in Values grid (this lets you hide columns, reorder, sort, etc. before export)
NEW: Plugin support added.
NEW: Added View | Plugins to explore available plugins
NEW: Added Base64 to Data interpreter under Strings section
NEW: Added Tools | Preferences
NEW: Option to show (and therefore export) RegBinary values as Base64 strings (enabled in Tools | Preferences)
NEW: Option to show (and therefore export) value slack as Base64 strings (enabled in Tools | Preferences)
NEW: Option to set custom date/time format for timestamps in Tools | Preferences
NEW: For RegUnknown value type, show the actual value of the Registry Type in hex and decimal.
NEW: Ability to double click offset in hex viewers to jump to the offset in either decimal or hex
NEW: When a plugin is added for a key or value, make it the active tab
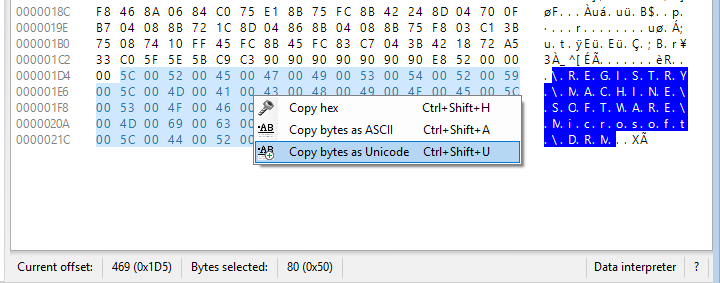
NEW: Hex viewer allows for selecting bytes and copying as hex, ANSI string (Windows 1252 code page), or Unicode string
NEW: When exporting value data, offer exporting in binary or string format
NEW: Allow for searching for many terms at once vs one at a time in Find dialog
NEW: Change messages count background color to
yellowwhen there are warning messages and
red when there are error messages. This color will be cleared when the Messages window is viewed.
CHANGE: Disable Bookmarks menu when on Available bookmarks tab
CHANGE: Clear any active filters before selecting bookmarked key
CHANGE: Set focus to last used search type on Find form
CHANGE: Sort bookmarks by name
CHANGE: Load hives when they do not have an nk record with a HiveRootEntry flag set. When this happens, an alternate method is used to find the root key
CHANGE: Put the newest search history items at the top of the list
CHANGE: Don't trust Header length when looking for hbins as sometimes Header length is wrong
CHANGE: Values grid filters use ‘contains’ vs ‘starts with’ as default
FIX: Add missing tooltip to Literal checkbox on Find form
FIX: Update hex position in hex type viewer when moving up and down rows vs only left and right
FIX: Correct issue when selecting hits in Find panel if the Registry keys tree was sorted when a virtual key existed (Associated Registry keys for example)
FIX: Handle rare issue when building virtual keys for 'Associated deleted records' where there is an active key and a recovered deleted key with the same name
FIX: Lots of tweaks and miscellaneous fixes
Thanks to all the beta testers and especially
David Cowen and
Jerod Alexander for their suggestions and feedback.
General changes
The following sections will cover the more important changes in this version of Registry Explorer. In addition to these high level changes, a lot of polish went into many different areas.
For example, bookmarks are now sorted by name which makes bookmarks easier to find in the list. In previous versions the bookmarks were listed in the order the bookmarks were read when Registry Explorer started up.
Search improvements
New in this version is the ability to enter more than one search term to look for. In previous versions, only one search term was allowed which meant if you had 10 things to search for you had to search 10 times.
Because of this new feature, the Find window was slightly redesigned. In the example below, we are searching for nine terms at the same time.
Protip: To initiate a search without having to click the 'Search' button, press enter twice after entering the last keyword.
After a search is conducted, the results are displayed as they were in the previous version. In this version, a new column was added, Hit Text, that shows which search term was found for a given key/value.
This allows you to group by each of the search terms by dragging the 'Hit Text' column to the appropriate spot, filter, sort, etc. When combined with other columns, like the 'Hit Location' column, you can quickly drill down into your results on a more granular basis.
Finally, the history has been updated to include multi-term searches.
Selecting an entry from history will populate the search terms in the 'Search for' box. Use Options | Clear recent searches to purge the history.
Exporting of values
The context menu for keys now allows for exporting of all values found under a given key to a multitude of formats.
The important thing to remember when exporting values is that the data is exported exactly as shown in the Values grid. This lets you change sorting, hide columns, reorder columns, etc. and have this reflected in the resulting file.
Here is an example of exporting the above key to Excel looks like when the Values grid looks as it does in the above screen shot:
If I were to drag the Value Slack column to the left of Value Name and sort on Value Name, the exported results would look like this (arrow and rectangle added for emphasis of course):
Here we can see the Value Slack is the first column and the data is sorted differently.
The same values exported to HTML would look like this:
New menu options
Options | Preferences
Several new options have been added and are available via Options | Preferences.
The top two options are self explanatory. The bottom option, Date/Time format, controls how timestamps are displayed throughout the program. As the format is changed, the example date/time below the box is updated in real time to show you what the new format would look like.
Changes to the Date/Time format will be reflected immediately in most places as new timestamps are displayed. To completely change over to a new timestamp format, restart Registry Explorer.
View | Plugins
To view all available plugins, use the View | Plugins menu option.
In the example below we can see that a total of 15 plugins were loaded and the AppCompatCache plugin is selected in the list.
Most of the plugin properties are self explanatory.
The 'Key paths' property determines what key paths this plugin will handle. In other words, if any of the keys listed are selected, the plugin will be activated. In this particular case, 'Value name' is also populated. This means that not only do one of the key paths have to be selected, but the AppCompatCache value must also be selected before the plugin will be executed.
Plugins must have at least one entry in 'Key paths' but 'Value name' is not required. When 'Value name' is empty, the plugin will be activated when one of the keys listed is selected.
User interface tweaks
In the lower right corner is a counter that indicates how many messages exist in the Messages window. This window can be seen by either clicking View | Messages or double clicking on the counter.
New in this version is color coding of the counter. Yellow indicates one or more warnings are present in the Messages window. Red indicates one or more errors are in the the Messages window.
After viewing the Messages tab, the background color will change to normal until the next warning or error is observed.
Other tweaks to the user interface include not forcing the slack viewer to be the active tab (i.e. keep the type viewer the selected tab as it will be used more often), disabling bookmarks menu when on the Available bookmarks tab, clearing filters prior to selecting a bookmark, and so on.
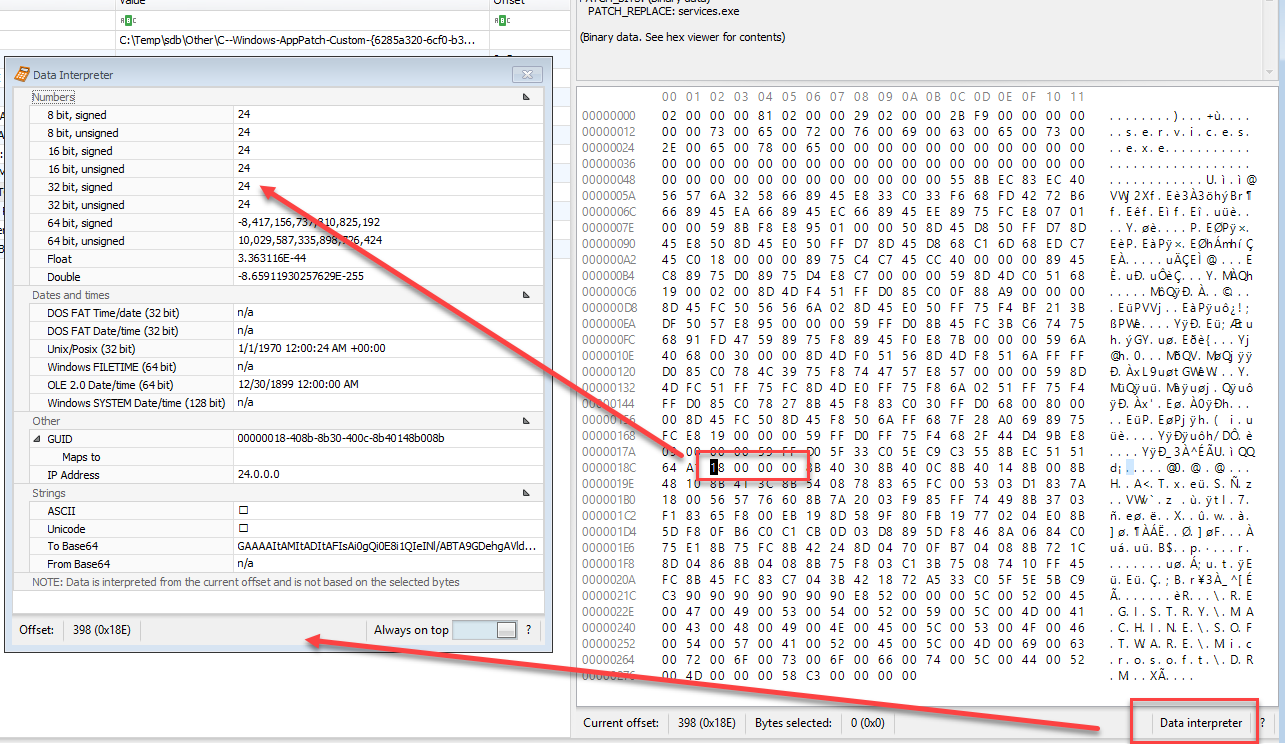
Copying of binary data to different formats
When looking at RegBinary values or value slack, the data is displayed in a hex editor as shown below.
In this release you can copy the selected bytes in one of three ways as shown in the context menu above.
This option augments the ability of the Data interpreter in that it allows you to copy any range of bytes in whatever format you choose.
Plugins
The biggest feature in this release is of course plugins! Plugins are basically a way to decode obfuscated data, correlate several different keys together, and so on.
All plugins also allow for exporting to Excel, reporting of any errors, etc. This will be demonstrated in the 7-Zip plugin section below.
There are two general flavors of plugins, those that handle a key and those that handle a key and value.
Key based plugins
When a key based plugin is activated, a new tab will be created next to the Values tab on the right side. This new tab will contain the processed values or other data based on what the plugin does. The ComDlg32 CIDSizeMRU plugin is an example of a key based plugin.
Key/value based plugins
When a key/value based plugin is activated, a new tab will be created next to the Type viewer tab below the Values tab. The AppCompatCache plugin is an example of a key/value based plugin.
Creating new plugins
All plugins are open source and are available
here. The manual for this release also contains a section on how to create plugins as well, so if that is something you are interested in (and I hope you are!), please check it out and hit me up with any questions.
Plugin walkthrough
Let's explore the plugins available in this release one by one.
Protip: Use the Available plugins tab to quickly click on bookmarks for keys that have plugins.
![]()
7-Zip history
This plugin is a key/value based plugin. The key is Software\7-Zip\Compression and the Value is ArcHistory. This value looks like this in its native format:
Looking at the binary data, we can see Unicode strings pointing to files 7-Zip has touched. When we click on the ArcHistory value, a new tab shows up next to Type Viewer, like this:
Once the plugin is finished processing the value we get back a listing of the data contained in a much more usable format.
If we look at the plugin results in a resized window we can see some of the other options available for each plugin:
Here we see a counter for the total number of rows, an Export (to Excel) button, and a ? which displays a tooltip showing details about the plugin.
If we export to Excel, we end up with something like this:
Should any errors be detected, this will be shown both with a status message to the right of the 'Total rows' area and via a drop down to the right of the question mark. Clicking on the Errors dropdown will show a list of all errors and the reason for them.
Ares P2P information
The Ares plugin works a bit differently in that it looks at several subkeys and values under the Software\Ares key.
For example, Ares search history looks like this:
but after the plugin processes the key, we get something like this:
Here we can see the search terms have been deobfuscated and are much more useful. We can additionally see other interesting bits of information such as the network ID, last connection time (converted from Unix epoch), port number, etc.
ComDlg32 CIDSizeMRU
This key can be used to glean information about program executions. Beyond the name of the executable as a Unicode string, there is not much more detail available.
This is what the values look like in their native state:
Like most keys of this sort, there is an MRU list. It looks like this:
In the above example, value 6 was last opened. Prior to that, values 4, 0x19, 1 and so on were opened.
If we look at value 6, we can see a Unicode string in the binary data, devenv.exe.
Since the MRUListEx value would be updated after a new value is added/changed, the key's last write timestamp would be updated to reflect this. Because of this, we can determine when the program in MRU 0 was executed/opened/etc.
Taking all of this information into account, this plugin generates the following results:
There are a few things to notice here. First, the output is, by default, in MRU order. Second, the executable in MRU 0 has an 'Opened on' value that is equal to the key's last write time.
This key has a few unknowns to it, primarily the GUIDs you can see above. To date, no one has been able to figure out where those GUIDs come from or resolve them to a more useful name.
File Extensions
This plugin processes all subkeys found under Software\Microsoft\Windows\CurrentVersion\Explorer\FileExts and extracts a list of programs that have been used to open a file extension. It also, when available, contains reference to the program a user prefers to open an extension with.
This is what the data would look like a given key. First, we have the OpenWithList key's values. Here you can see a list of values and an MRU.
Some extensions have another subkey, OpenWithProgids, that contains pointers to programs vs executable paths.
Finally, some extensions contain a UserChoice subkey that looks like this:
With all of this information in hand, the plugin then generates a list of every extension and program used to open said extensions when the FileExts key is selected. The resulting data looks like this:
Finally, here are a few examples where the 'User Choice' column is populated.
As with all plugins, the results can be exported to Excel and used for futher analysis.
First folder
This plugin displays program executables and optionally, the first folder to select for said program.
It looks like this normally:
![]()
We can see each value is RegBinary and in looking at the hex viewer at the bottom, Unicode strings are present. We also have an MRU list.
The plugin processes all of the values and we end up with this:
![]()
Like other plugins we have already seen, the list is sorted by MRU order and MRU 0 has its Opened On column populated.
ComDlg32 LastVisitedMRU
This plugin extracts executables along with a corresponding directory path used by the executable. It works similar to other ComDlg32 keys. Plugin output looks like this:
ComDlg32 LastVisitedPidlMRU/LastVisitedPidlMRULegacy
This key is similar to the previous plugin in that it stores executables and a path associated with a given executable. The difference with this plugin is the amount of detail that is stored about the path.
Here is what the data looks like normally:
In the example above, the data for value 2 is displayed in the Type viewer. In the hex display, several interesting bits of information are highlighted. The first, 14 00 1F, is the size and signature for a shell item GUID. The second, 04 00 EF BE, is the signature for a BEEF0004 extension block. This extension block contains timestamps, MFT entry and sequence numbers, and path information.
If you have looked at ShellBags Explorer you will have seen some of these same signatures. Likewise, if you have used ShellBags Explorer, you know how much rich detail is present in shell items.
When this plugin runs, its output looks like this:
Here we can see the MRU position, executable name, and absolute path that was accessed. When an invididual value is selected in the plugin output, a new tab is displayed below the plugin output, next to the Type viewer, that looks like this:
Notice the Absolute Path column is made up from the diffferent parts of the details presented.
This data is displayed as each value is selected in the plugin output. It is possible however, to view the details of each value in the grid, but it requires the Details column to be unhidden. To do this, right click on the column headers and choose 'Column Chooser.'
The Customization box for the grid will be shown. From here, click and hold the mouse button on the Details column, then drag it anywhere you want in the grid.
This will then show the Details column in the main grid, like this:
Notice the information in the above screenshot is the same we saw above when the Details tab was shown next to the Type viewer.
One reason you may want to show the Details column is that you can then filter on anything within it. Perhaps you are interested in any entries with an MFT entry number of 0x25C60. You can simply enter this value in the Details filter below the column header and any matching rows will be displayed, like this:
Here you can see the filter has returned one row, value 20, as being a match. Additionally, you can see the criteria used for the active filter and an Edit Filter button is displayed. These options allow you to toggle the filter (by checking or unchecking the checkbox to the left of the filter) or editing more complicated filters.
One thing to keep in mind is that it is NOT necessary to include the Details column manually before exporting. When plugins with details are found, the Details column will be automatically hidden before exporting the data so you will always have the Details in the Excel document.
ComDlg32 OpenSaveMRU
The OpenSaveMRU key maintains a list of folders and files, sorted by extension, that have been accessed.
The OpenSaveMRU key contains a list of recently accessed folders. Below is an example of what the data under an extension subkey looks like:
Notice we have an MRU present as we have seen before.
When all of this information is put together by the plugin, we end up with the following (blurry sections not included):
We again have our results sorted in MRU order. The results can of course be sorted and filtered depending on your needs.
ComDlg32 OpenSavePidlMRU
This plugin works exactly as the OpenSaveMRU plugin does but we gain the additional details as we saw with the previous Pidl plugin.
This is another plugin that has a Details column which is initially hidden.
Recent documents
This plugin works in a similar manner as the plugins we saw from ComDlg32 in that the main key has subkeys which contain values (including an MRU) that tracks recently opened files and folders.
All of the values are RegBinary and look something like this:
The RecentDocs key contains the most recently accessed items regardless of extension. Each subkey contains references to files with a given extension. There is also a Folder subkey that contains recently accessed directories.
When this plugin is finished processing all of the data, we end up with this:
This is a plugin that has benefited from community feedback. Initially this plugin was sorted by MRU and it was left to the analyst to use the data in the way that made the most sense to them.
Not too long ago however, a
conversation happened on Twitter that caught my attention. Based on the back and forth between several people, I tweaked the output of this plugin.
Notice that the output is not strictly in MRU order like some of the other plugins we have seen. This plugin is designed to mimic the technique outlined by
Dan Pullega which can be found
here.
The idea is using the recent documents from the main RecentDocs key and the MRU position 0 timestamps (that work exactly as we have already discussed), a timeline can be built that lets you infer a range (and often a small range) of time a particular document was opened, even if it was not MRU 0 for a given extension.
For more details on this technique and why it works, please read
Dan's post.
Thanks to Dan for the idea and for Juan/Phil/Eric's efforts at automating this process with their scripts.
RunMRU
This is a very simple plugin that turns this:
Into this:
User accounts
This plugin works against a SAM hive and correlates several different pieces of information together to build its output.
When the SAM\Domains\Account\Users key is selected, the following data is returned by the plugin:
![]()
This plugin works by looking at the subkeys under the Names subkey and correlating that information to the F and V values found under Users subkeys (other than the Names key). It extracts information from the F and V values and builds what you see above.
For full details as to how this plugin works, see the source code
here.
TimeZoneInformation
This plugin is for SYSTEM hives and looks at the ControlSet00X\Control\TimeZoneInformation key.
This key looks like this normally:
After the plugin processes things, we get this:
When designing this plugin I found several references to how some of the values under this key worked on the Interwebs. As I started coding, I noticed that the resulting start and stop times matched something else I was familiar with seeing on a regular basis in X-Ways Forensics.
The image below is the information available in X-Ways Forensics for UTC-7, Mountain Time:
If we compare the daylight start and daylight end times from the plugin to what we see here, we can see the information matches (albeit in a slightly different format). Its always a good thing to validate your output!
UserAssist
The UserAssist key (and subkeys) will look something like this:
Notice that the subkeys with a GUID name contain a Count subkey. The values shown above are what we find in one of these Count keys. As you know, UserAssist value names are encoded using ROT-13.
This particular plugin is activated whenever a key matching this pattern is selected:
Software\Microsoft\Windows\CurrentVersion\Explorer\UserAssist\*\Count
Notice the * in there. This allows the plugin to process any of the Count keys regardless of which GUID is selected.
When one of these Count keys is selected, the plugin decodes the value names and extracts other bits of information from the value's binary data.
Here we can see the original, obfuscated value name and the decoded value. We also get a Run counter and, when available, a Last executed timestamp.
AppCompatCache
And last, but not least, we have the AppCompatCache plugin. This plugin is based on both a key, ControlSet00X\Control\Session Manager\AppCompatCache, and a value, AppCompatCache.
This value looks like this in its native form:
![]()
When the AppCompatCache value is selected, a new tab shows up next to the Type viewer, like this:
![]()
The output is very similar to what my AppCompatCacheParser program extracts.
That's it!
Whew! We made it to the end! You can get Registry Explorer from the
usual place.
Enjoy and PLEASE let me know what other plugins you want.